Exploring the Applications and Implications of Social Media and Demographic ResearchCologne, Germany, 17 May 2016
The IUSSP Scientific Panel on Big Data and Population Processes organized a workshop on Social Media and Demographic Research at the 10th International AAAI Conference on Web and Social Media (ICWSM-16), in Cologne, Germany, on May 17, 2016. The workshop was supported by grants from the William and Flora Hewlett Foundation to the IUSSP and the Population Association of America (PAA) to support demographers' participation in the Data Revolution. The goal of the workshop was to bring together population researchers and data scientists to discuss the applications and implications of social media for demographic research, and foster communication between these two communities.
The day was divided into three sessions: "Population Estimates", "Migrations", and "Demography and the Web: New Directions". Each session brought together a range of presenters – demographers, sociologists, computer scientists – to share their work. A number of presentations offered promising approaches for tracing migration patterns and measuring flows of migrants between countries, while taking advantage of the new potential that social media can offer (real-time, availability in data-poor environments, insight into opinions and beliefs, etc). They also proposed techniques for matching digital data with census and survey data, and determining the age, gender, and income breakdown of users of a certain website, set of apps, or social network – this in turn might be used to infer demographic characteristics of geographic areas.
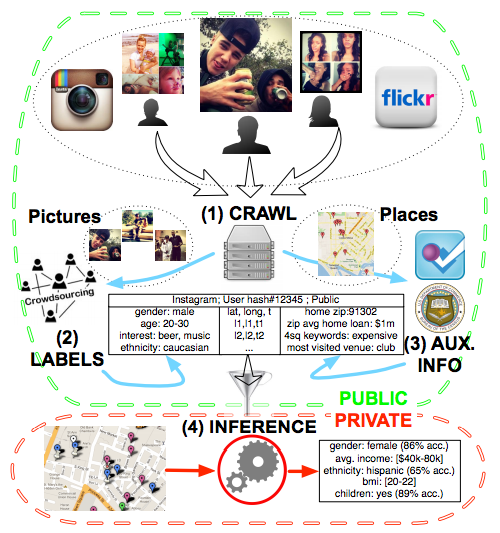
For example, Chris Riederer's work with demographic estimates based on Instagram profiles [see diagram below], presented by Augustin Chaintreau, shows that the photos, text, and geotags from Instagram profiles can be used to determine age, race, and gender for census tracts in and around Manhattan. The authors suggest using this type of data to study segregation in daily interactions (i.e. across all locations) instead of just using home ZIP code as is usually the case.
Figure 1: Methodology overview. A mobility dataset can be built in the following steps: (1) Public user profiles of a photosharing service are crawled and photo metadata are extracted into a database (Data Collection). (2) Corresponding photos are labeled (with labels for ethnicity, gender, etc.) by crowd workers in an online labor marketplace (User Labeling). (3) The dataset is further enhanced with auxiliary data, e.g., with the information that a certain location is close to a restaurant (Adding Auxiliary Information). (4) The dataset can then be used to analyze attributes on various demographic levels or train and test classifiers for individual inferences.
Perhaps even more interesting than what these new data sources can do, however, is the discussion of where they might fail. Several of the presentations took a deeper look at how these models can create or reinforce bias. In the case of the Instagram study, for instance, although the model can determine gender with fairly high accuracy and confidence, the model is much more problematic for race: not only is it less accurate, but it also tends to overstate the confidence on its predictions. This bias can come from a variety of sources: people in a majority group may be more likely to post photos that identify them as part of the majority; human observers may accidentally (or intentionally) provide biased interpretations when coding training data for the models; machine learning algorithms may "learn" from bias in the data they are trained on, and reinforce that bias through feedback loops; etc. This demonstrates that seemingly "neutral" algorithms may in fact systematically under-represent specific groups, even when accounting for other forms of bias (such as over- or under-representation of certain groups in Instagram's user-base).
Gabriel Pestre, Emmanuel Letouze and Emilio Zagheni presented some of Data-Pop Alliance’s work on sample bias correction [see slides] using cell-phone data from Orange's D4D Challenge and Census data from Senegal's Agence Nationale de la Statistique et de la Démographie, which will be presented later this month at the World Bank's Annual Bank Conference on Development Economics 2016: Data and Development Economics (ABCDE).
The day ended with a very engaging roundtable discussion on important questions in the area of social media for demographic research, with particular focus on which real-world problems this emerging field can hope to address, and what IUSSP and other professional organizations can do to help advance these research goals. Participants mentioned nowcasting as an area of great potential, especially for deepening our understanding of migration. They also expressed a need for better materials and tools – such as a primer on "What is Social Media for Demographic Research?" – to help focus the discussion between computer scientists and demographers on how the field conceives of itself, what important research questions it hopes to explore, and which approaches are most appropriate for controlling bias, understanding/communicating uncertainty, and evaluating/comparing models.
For more information about this meeting and its follow-up, IUSSP members may contact Emilio Zagheni (emilioz@uw.edu).
See also:
Funding: Financial support for the meeting was provided by the William and Flora Hewlett Foundation. |
|