Médias sociaux et recherche démographique : applications et implicationsCologne, Allemagne, 17 mai 2016
Le Comité scientifique de l’UIESP sur Big Data et processus démographiques a organisé un atelier sur Médias sociaux et recherche démographique à la 10e Conférence internationale de l’AAAI (Association pour le développement de l’intelligence artificielle) sur Web et médias sociaux (ICWSM-16), à Cologne (Allemagne) le 17 mai 2016. Cet atelier était financé par une subvention de la Fondation William et Flora Hewlett à l’UIESP et à la Population Association of America (PAA) pour encourager la participation des démographes à la Révolution des données. L‘atelier avait pour objectif de rassembler des chercheurs en démographie et des spécialistes des données pour discuter des applications et implications des médias sociaux pour la recherche en démographie et favoriser la communication entre ces deux communautés scientifiques.
La journée était divisée en trois séances : "Estimations de population", "Migrations", et "Démographie et Web : nouvelles directions". Chaque séance a rassemblé divers intervenants : démographes, sociologues, informaticiens. Plusieurs présentations ont décrit des approches prometteuses pour suivre les parcours de migration et mesurer les flux de migrants entre pays, en se servant des nouvelles possibilités offertes par les médias sociaux (observation en temps réel, disponibilité dans des environnements pauvres en données, aperçu des opinions et croyances, etc.). Elles ont aussi proposé des techniques pour coupler les données numériques avec les recensements et les données d’enquêtes et déterminer la distribution par âge, sexe et revenu des utilisateurs de certains sites Web, d’applications, ou de réseaux sociaux, ce qui peut ensuite être utilisé pour en déduire les caractéristiques démographiques d’aires géographiques.
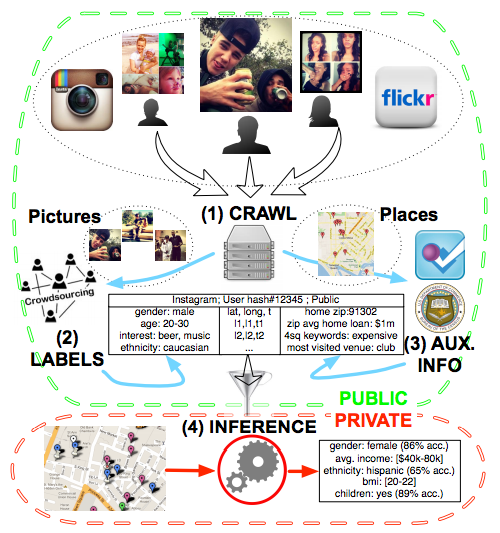
Par exemple, les travaux de Chris Riederer sur des estimations démographiques fondées sur les profils Instagram [voir le diagramme ci-dessous], présentés par Augustin Chaintreau, montrent que les photos, le texte, et les balises de localisation des profils Instagram peuvent servir à déterminer l’âge, la « race », et le sexe pour des secteurs de recensement dans et autour de Manhattan. Les auteurs proposent d’utiliser ce type de données pour étudier la ségrégation dans les interactions quotidiennes (c’est à dire dans l’ensemble des lieux fréquentés) plutôt que d’utiliser simplement le code postal du domicile comme c’est habituellement le cas.
Figure 1: Aperçu méthodologique. Un ensemble de données sur la mobilité peut être construit selon les étapes suivantes: (1) Les profils publics d’utilisateurs d’un service de partage de photos sont extraits et les métadonnées des photos sont importées dans une base de données (Collecte des données). (2) Les photos correspondantes sont marquées (avec des étiquettes pour l’ethnicité, le sexe, etc.) par des crowd workers dans un marché du travail en ligne (Marquage des utilisateurs). (3) La base de données est ensuite enrichie avec des données complémentaires, par exemple l’information qu’un certain lieu est proche d’un restaurant (ajout d’information complémentaire). (4) La base de données peut alors être utilisée pour analyser les caractéristiques à différents niveaux démographiques ou pour former et tester des classificateurs d’inférences individuelles.
Peut-être encore plus intéressant que l’apport potentiel de ces nouvelles sources de données se pose aussi la question de savoir en quoi elles peuvent être trompeuses. Plusieurs présentations ont examiné plus à fond comment ces modèles peuvent créer ou aggraver les biais. Dans le cas de l’étude sur Instagram, par exemple, bien que le modèle puisse identifier le sexe avec une assez grande précision et confiance, il est beaucoup moins sûr pour identifier la « race » : non seulement il est moins précis mais il a aussi tendance à surestimer le degré de confiance de ses prédictions. Ce biais peut provenir de diverses causes : les individus appartenant à un groupe majoritaire peuvent être plus susceptibles de poster des photos qui les montre clairement comme faisant partie de la majorité ; les observateurs humains peuvent accidentellement (ou volontairement) fournir des interprétations biaisées quand ils codent les données de référence pour les modèles ; les algorithmes d’apprentissage automatique peuvent « apprendre » à partir de données biaisées sur lesquelles ils sont entrainés et renforcer ces biais par des boucles de rétroaction ; etc. Ceci est la preuve que des algorithmes qui semblent « neutres » peuvent en réalité systématiquement sous-représenter certains groupes particuliers, même si l’on tient compte d’autres formes de biais (tels que la sur- ou la sous-estimation de certains groupes dans la base des utilisateurs d’Instagram).
Gabriel Pestre, Emmanuel Letouzé et Emilio Zagheni ont présenté un aperçu des travaux de la Data-Pop Alliance sur les corrections des biais d’échantillonnage [voir diapos] en utilisant les données des téléphones mobiles du Challenge D4D d’Orange et des données du recensement de l’Agence Nationale de la Statistique et de la Démographie du Sénégal. Ces résultats seront présentés à la fin du mois de juin à la Conférence bancaire annuelle sur l’économie du développement de la Banque mondiale (Annual Bank Conference on Development Economics 2016: Data and Development Economics (ABCDE).
La journée s’est achevée par une table-ronde très animée portant sur des questions essentielles dans le domaine de l’utilisation des médias sociaux pour la recherche démographique avec une attention particulière sur les problèmes du monde réel que ce champ émergent peut aider à traiter et sur la manière dont l’UIESP et d’autres organisations professionnelles peuvent aider à faire avancer ces objectifs de recherche. Les participants ont évoqué la prévision immédiate (nowcasting) comme un domaine de grand potentiel, notamment pour améliorer notre connaissance des migrations. Ils ont aussi exprimé un besoin de meilleurs matériels et outils, tels qu’un texte introductif sur "Médias sociaux et recherche démographique?" – pour aider à orienter la discussion entre informaticiens et démographes vers une meilleure définition du champ, vers les questions de recherche qu’il peut aider à explorer, et vers les approches qui sont les plus appropriées pour contrôler les biais, comprendre et faire comprendre la notion d’incertitude et évaluer/comparer les modèles.
Pour plus d’information sur cette réunion et ses suites, les membres de l’UIESP peuvent contacter Emilio Zagheni (emilioz@uw.edu).
Voir aussi :
Financement : La réunion a bénéficié du soutien financier de la Fondation William et Flora Hewlett. |
|