L’utilisation des données bibliométriques dans la recherche démographiqueGroningue, Pays-Bas, 29 juin 2022
L'atelier sur « L'utilisation des données bibliométriques dans la recherche démographique » a été organisé par le Comité de l'UIESP sur la démographie numérique le mercredi 29 juin 2022 de 9h00 à 12h45 CET en marge de la Conférence européenne sur la population 2022 (EPC2022), à l'Université de Groningue et en ligne.
Les instructeurs pour cet atelier étaient Aliakbar Akbaritabar, chercheur (postdoc) et titulaire de la chaire de recherche sur les migration et la mobilité au Max Planck Institute for Demographic Research (MPIDR), et Xinyi Zhao, doctorante au Max Planck Institute for Demographic Research (MPIDR ) et l'Université d'Oxford.
Tous les supports de l'atelier ainsi que les instructions ont été partagés avant l'événement avec les participants et ceux-ci sont disponibles sur ce référentiel GitHub.
L'ordre du jour de l'atelier comprenait différents sujets allant de l'introduction aux données bibliométriques, aux sources de données disponibles et à leurs avantages et inconvénients, au prétraitement et au complètement de ces données pour des études de cas spécifiques, aux résultats de certaines études de cas discutées et à une table ronde avec des conférenciers invités à présenter leurs travaux utilisant ce type de données. L'atelier a également abordé les limites et les écueils de ces sources de données. Le matériel de l'atelier comprenait des exemples de sources de données, des scripts R, Python et SQL avec des exemples reproductibles pour guider ceux qui souhaitent avoir une expérience pratique des données bibliométriques.


La première partie de l'atelier a permis de présenter aux participants présents ou en ligne en quoi consistent les « données bibliométriques » et comment les chercheurs peuvent utiliser ces données pour la recherche démographique. L'introduction couvrait la littérature et les études sur les « migrations pour études », qui sont parmi les thèmes les plus étudiés en utilisant des données bibliométriques pour la recherche démographique.
La deuxième partie de l'atelier portait sur les recherches menées au MPIDR par des chercheurs affiliés, anciens ou invités sur les « migrations universitaires » dans différents contextes.

Emilio Zagheni (MPIDR) a débuté par une introduction générale sur les avantages de l'utilisation des données bibliométriques longitudinales et à grande échelle pour répondre aux questions démographiques. Il a mis l'accent sur une idée simple mais susceptible d’être étendue pour retracer la mobilité des universitaires par le changement d'adresse d'affiliation universitaire. Il a également annoncé de nouvelles activités à venir au MPIDR et le développement d'une base de données accessible au public sur les migrations universitaires.
Ensuite, Andrea Miranda-González de UC-Berkeley a présenté ses résultats sur les migrations interne au Mexique, suivi par Asli Ebru Sanlitürk (chercheur au MPIDR), sur l'effet du Brexit sur les migrations universitaires vers et depuis le Royaume-Uni.

Maciej J. Dańko (MPIDR) a ensuite présenté une approche globale sur le développement et les migrations internationales des universitaires.

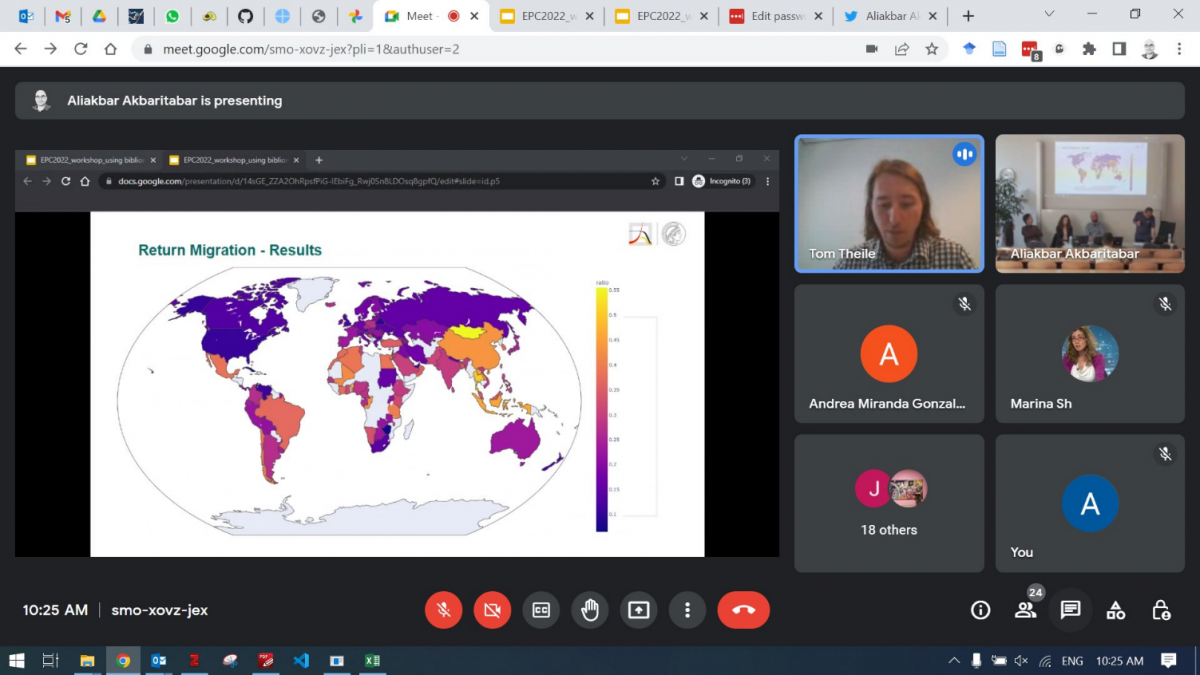
Tom Theile (MPIDR) a fait ensuite présentation sur les tendances dans les migrations internationales de retour dans le monde.
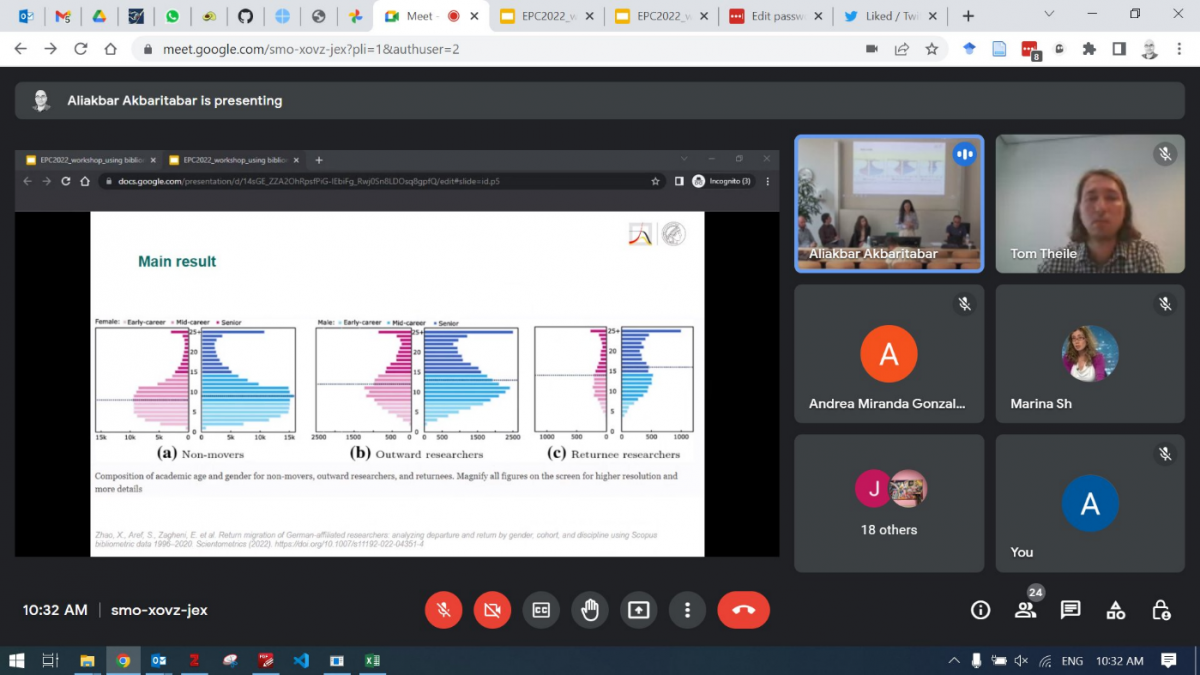
Ensuite, Xinyi Zhao (MPIDR) a présenté un chapitre de sa thèse de doctorat traitant de la perspective de genre dans les migrations universitaires internationales et les migrations de retour en Allemagne.

En tant que dernier orateur du panel, Aliakbar Akbaritabar (MPIDR) a expliqué la nécessité d'intégrer les systèmes de migrations internes et internationaux dans un cadre unique qui qui n’existe pas jusqu’à maintenant en raison des limitations des données. Il a souligné qu'en utilisant des données bibliométriques longitudinales et à grande échelle ces limitations peuvent être surmontées dans le cas des universitaires dans le monde entier.
La séance s’est poursuivie avec une discussion ouverte et des questions-réponses entre les participants sur place et en ligne.

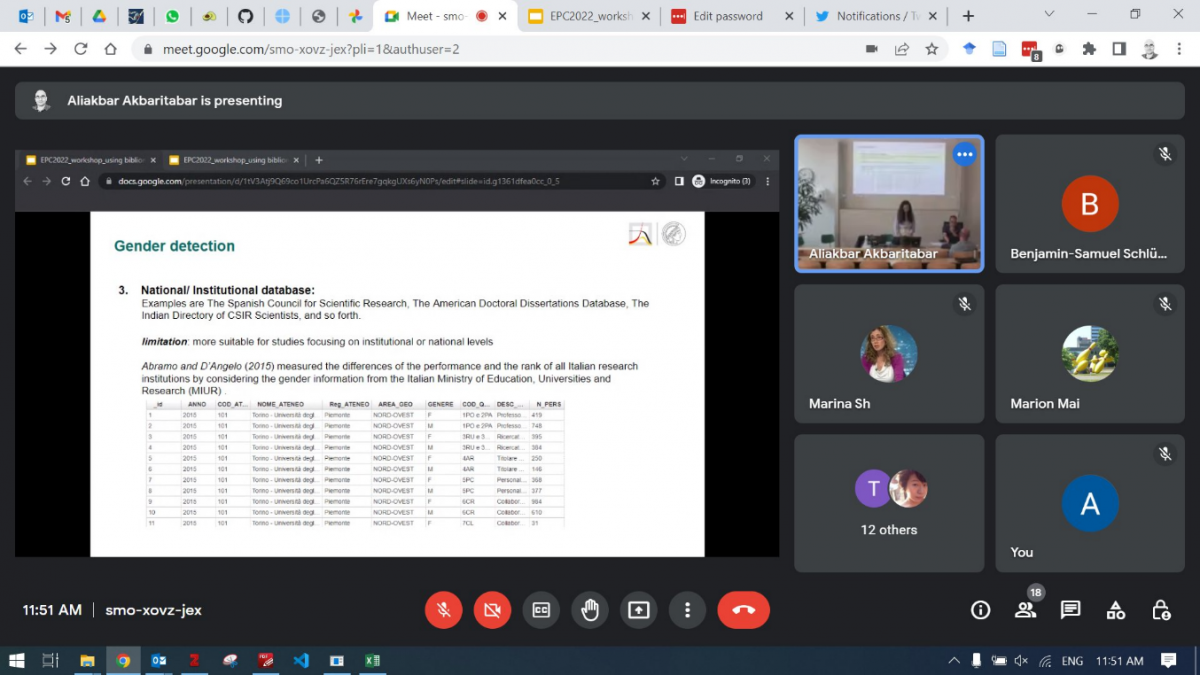
L'atelier s'est poursuivi sur les points suivants de l'ordre du jour, avec une introduction aux sources de données disponibles, en particulier les données accessibles au public et une introduction au traitement des données bibliométriques pour la recherche démographique : récupération des données, prétraitement des données et réorientation en fonction des questions de recherche. Xinyi Zhao a discuté de son approche pour compléter les données bibliométriques en déduisant le sexe des universitaires à l'aide de leur prénom.
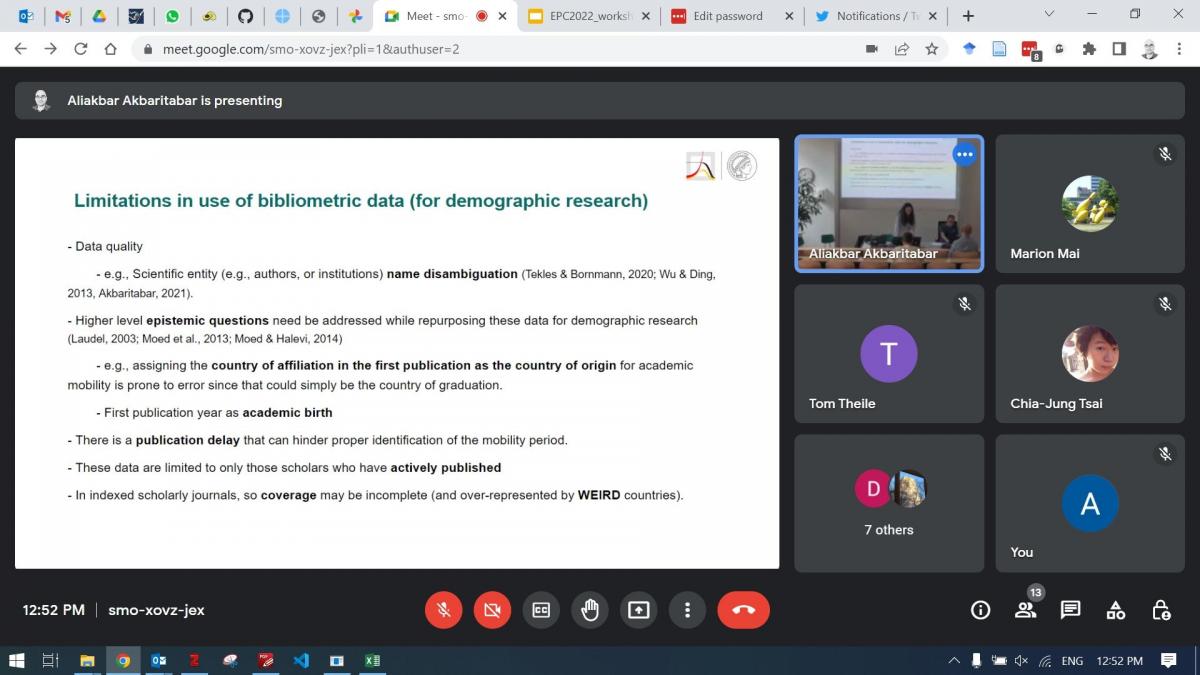
L'atelier s'est conclu par une discussion sur les limites des données bibliométriques. Des solutions à certains des problèmes de qualité des données ont été discutées et les lacunes liées à la couverture ou à la surreprésentation de pays ou de langues spécifiques dans ces bases de données ont été évoquées.
En raison de contraintes de temps, une session pratique avec codage en direct n'a pas été effectuée pendant l'atelier, mais pour les participants qui avaient reproduit les résultats à l'aide des supports de l'atelier et de scripts R ou Python, des sessions de questions-réponses ont été attribuées pour discuter des problèmes potentiels ou résoudre les erreurs.
Un flux en direct de tweets sur la conférence EPC2022 et sur l'atelier a été publié en ligne montrant les impressions des participants sur l'atelier.
Sans surprise, #BiblioDemography était parmi les hashtags les plus utilisés lors de la conférence aux côtés du hashtag de la conférence #EPC2022 (voir l'analyse de NodeXL de ces flux en direct.)

|