Using bibliometric data in demographic researchGroningen, the Netherlands, 29 June 2022
The workshop on "Using bibliometric data in demographic research" was organized by the IUSSP Panel on Digital Demography on Wednesday 29 June 2022 from 9:00 to 12:45 CET as a side-meeting of the European Population Conference 2022 (EPC2022), at the University of Groningen and online.
The instructors of the workshop were Aliakbar Akbaritabar, research scientist (postdoc) and research area chair on migration and mobility at the Max Planck Institute for Demographic Research (MPIDR), and Xinyi Zhao, PhD Candidate at the Max Planck Institute for Demographic Research (MPIDR) and University of Oxford.
All workshop materials were publicly accessible and shared with participants along with participation instructions prior to the event through this GitHub repository.
The workshop agenda included a basic introduction to bibliometric data, available data sources and their advantages and shortcomings, complemented by discussion of the results of some case studies. A panel discussion by invited speakers showcased what researchers had done using this type of data. The workshop also covered the limitations and pitfalls of these data sources. Workshop materials included example data sources, R, Python and SQL scripts with replicable examples to guide those wishing to have a hands-on experience with bibliometric data.


The first part of the workshop was dedicated to introducing online and onsite participants to “bibliometric data” and how researchers can use this data for demographic research. The introduction covered studies of “scholarly migration” which are among the most investigated topics using bibliometric data for demographic research.
After a preliminary introduction, the second part of the workshop focused on research carried out at MPIDR by affiliated, former, or visiting researchers on “scholarly migration” in different contexts.

Emilio Zagheni (MPIDR) began the panel discussion with a broad introduction on the benefits of using large-scale and longitudinal bibliometric data to answer demographic questions. He emphasized a simple but scalable approach to trace scholarly mobility through changes in academic affiliation addresses. He also announced upcoming activities at MPIDR to develop a publicly available database of scholarly migration.
Next, Andrea Miranda-González (UC-Berkeley) presented her results on internal migration in Mexico. This was followed by Asli Ebru Sanlitürk’s (MPIDR) talk on Brexit’s effect on scholarly migration to and from the UK.

Maciej J. Dańko ( MPIDR) followed with a global perspective on development and international scholarly migration.

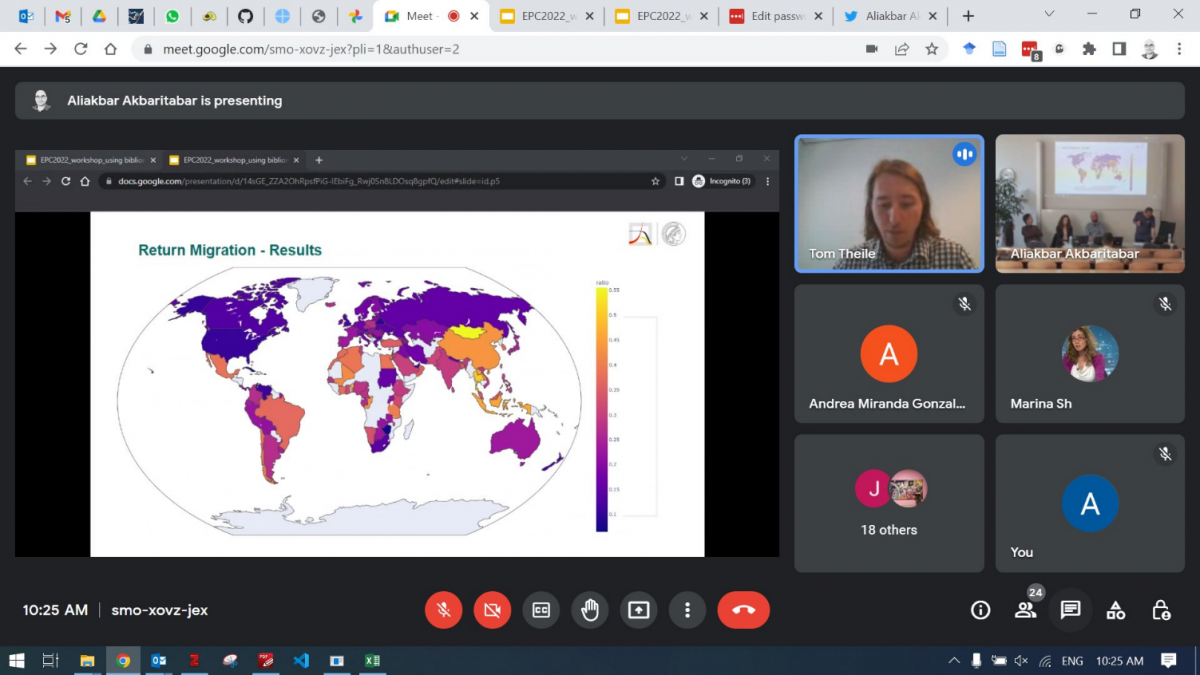
Tom Theile (MPIDR) presented Trends of return international migration worldwide.
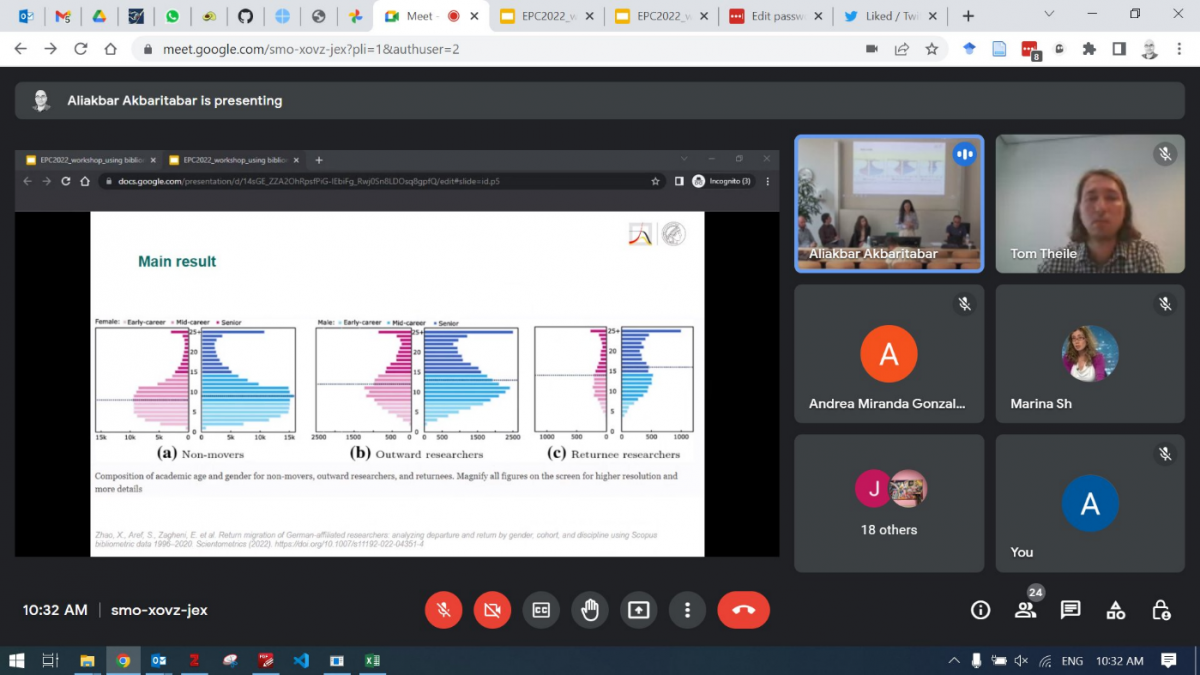
Next Xinyi Zhao (MPIDR) presented a chapter of her PhD thesis providing a gender perspective on international scholarly migration and return migration to Germany.

The last speaker of the panel, Aliakbar Akbaritabar (MPIDR) highlighted the necessity of integrating internal and international systems of migration in a unique framework, which does not yet exist due to data limitations. He emphasized that using large-scale and longitudinal bibliometric data can address this limitation in the case of scholars worldwide.
The Panel continued with an open discussion and Q&A among the onsite and online workshop participants.

The workshop then turned to an introduction to available data sources, especially publicly available data and how to handle bibliometric data for demographic research: data retrieval, data pre-processing and repurposing based on research questions. Xinyi Zhao discussed her approach in complementing bibliometric data by inferring gender of scholars using the first name.
The workshop concluded with a discussion of the limitations of bibliometric data. Solutions to some of the data quality issues were discussed and shortcomings due to coverage, or over-representation of specific countries or languages in these databases were touched upon.
Due to time limitations, a hands-on session with live coding was not carried out during the workshop but for those participants who had replicated the results using workshop materials and R or Python scripts, Q&A sessions were allocated to discuss potential problems or troubleshoot errors. 
A live stream of tweets about the EPC2022 conference and the workshop were published online that shows participants’ impressions of the workshop.
Not surprisingly, #BiblioDemography was among the most used hashtags alongside the #EPC2022 conference hashtag during the conference (see NodeXL’s analysis of these livestream).

|